

Addressing the Risks of Modern Generative AI Systems
AI systems are changing the way we work, interact, and innovate – but they aren’t without risk. Whether it’s a chatbot giving unsafe medical advice, generating violent or inappropriate content, or even inadvertently recommending a competitor’s product, these failures can erode trust, damage reputations, and, in some cases, put people at risk.
Two core challenges to building AI systems include identifying content safety violations and prompt injection attacks. Content safety involves identifying violent, hateful, or otherwise inappropriate inputs and preventing outputs that are harmful or potentially dangerous and could pose risks to users, violate ethical or business guidelines, or are inappropriate given the context. Prompt injections are deliberate attempts to manipulate AI systems into behaving in ways outside of their intended use. Addressing these risks is critical to ensuring the development of properly safeguarded AI systems.
A New Approach to AI Safety Classification
At Neudesic, we believe existing approaches for safety classification are not good enough. Many existing approaches are focused on identifying clear-cut hate speech or violence, but often miss language that is inappropriate for a business context. Other approaches are great at identifying nefarious prompt injection attacks, but often miss prompt injections that violate business rules or the intended use of the system. Effectively solving these challenges requires a much better approach, one that is highly accurate, scalable, and adaptable to real-world AI systems. That’s why Mason Sawtell, Tula Masterman, Sandi Besen, and Jim Brown authored the paper Lightweight Safety Classification Using Pruned Language Models, introducing Layer Enhanced Classification (LEC) – a method combining the computational efficiency of simple machine learning classifiers with the robust language understanding of Language Models. They worked alongside Erin Sanders, our Responsible AI lead at Neudesic, to overcome challenges related to content safety and prompt injection classification.
LEC effectively identifies content safety issues and prompt injection attacks with greater accuracy than existing solutions and without requiring massive training datasets. In fact, with as few as 15 examples, LEC outperforms leading models like GPT-4o and Meta’s Llama Guard 3 (1B and 8B) on content safety identification tasks while running at a fraction of the cost. For identifying prompt injections, LEC models outperformed GPT-4o using 55 training examples and special purpose model deBERTa v3 Prompt Injection v2 using as few as 5 examples.
Whether you’re working with closed-source models like OpenAI’s GPT series or open-source models like IBM’s Granite series, LEC can be adapted to meet your needs by either integrating directly into the inference pipeline of open-source models or working alongside closed-source models to provide safety checks before and after the model generates a response.
The implications of LEC go beyond AI safety. While the initial research was focused on responsible AI based tasks, the approach can be modified to take on other types of text-classification like sentiment analysis, intent detection, and product categorization.
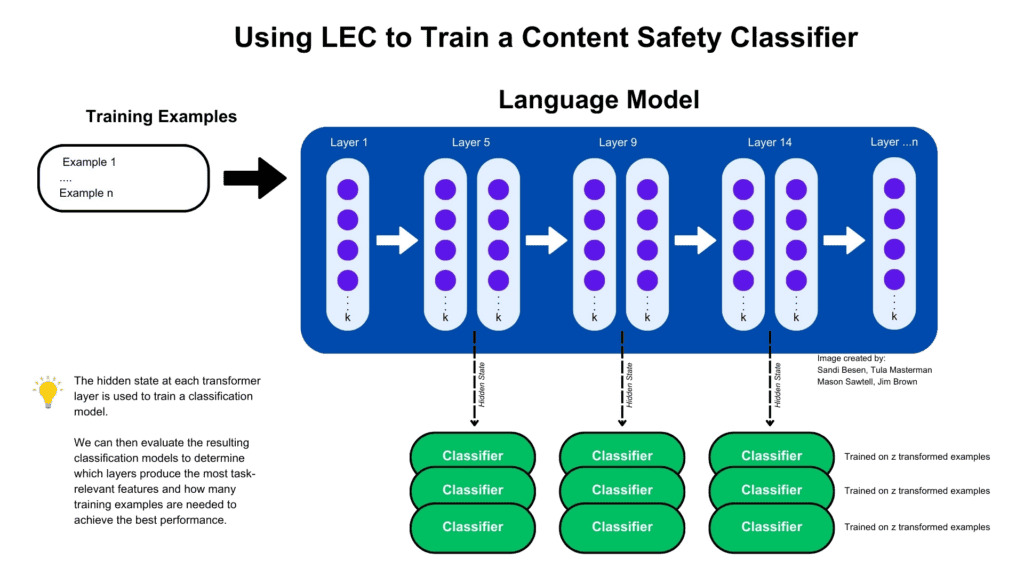
Figure 1: Illustration of training approach
How can Businesses Use Layer Enhanced Classification (LEC)?
We believe that LEC has many promising applications for enabling the safe and responsible deployment of Generative AI solutions for both new implementations and existing systems. The LEC process can be applied to multiple stages of Language Model based workflows including before, during, and after a model generates an output as well as across multiple stages of agent-based applications.
Working with Closed-Source Models
For use cases leveraging closed-source models like OpenAI’s GPT-4o or o1, where the model architecture is not publicly available, and modifying the model’s inference pipeline is not feasible, a lightweight task-specific classification model trained using LEC can be used as a safeguard before sending the user input to the LLM. This can prevent any unsafe content or prompt injections from ever reaching the model. Similarly, once the LLM generates an output, this response can be sent back through the appropriate classifiers to make sure no unsafe content is present in the reply.
Augmenting Open-Source Models
For use cases leveraging open-source models where the underlying model architecture is accessible, the LEC approach can be directly applied to that model. This means the same model can be used to create the features needed to identify content safety and prompt injections as well as generate the final response for the user.
Safeguarding AI Agent Systems
In agent-based scenarios, LEC offers several layers of protection. First, it can be used to determine whether the agent should work on a given request. Next, it can be used to validate suggested tool calls or intermediate responses adhere to content safety requirements. If an agent retrieves additional information from a tool call, search engine, or internal data source, LEC can help determine if the retrieved information contains violations before the agent uses it.
The application of LEC in multi-agent setups depends on the models used for each agent. For instance, an agent using a closed-source model would rely on separate classifiers to run safety checks before and after generating its response. By contrast, an agent using an open-source model could be adapted to integrate the LEC process directly into its workflow, simultaneously generating outputs and performing safety checks within the same inference.
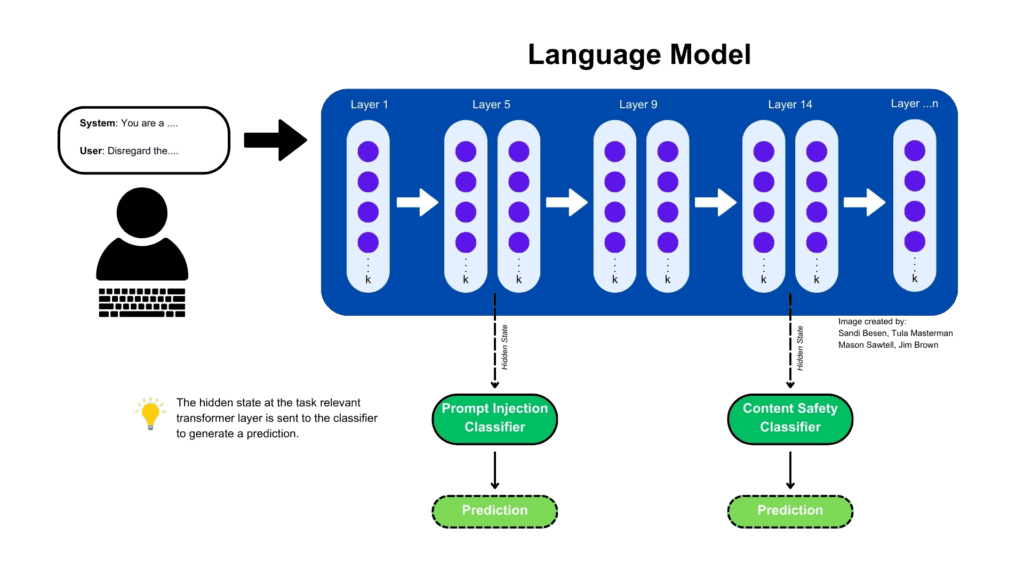
Figure 2: Illustration of generating the predictions for a given input
Conclusion
Neudesic’s Layer Enhanced Classification (LEC) provides a breakthrough approach for two pressing Generative AI safety challenges: content safety violations and prompt injection attacks. With its focus on efficiency, accuracy, and adaptability, LEC provides businesses with a practical solution to safeguard their Generative AI systems.
In future articles we will dive into the practical applications of LEC, including demonstrating the ability of this approach to effectively enforce an AI system’s intended use and avoid business inappropriate language, going beyond the tools available in the marketplace. We will also cover how this approach could extend to other types of classification problems like groundedness detection.
Dive into the research in the full paper now available on ArXiv: https://arxiv.org/abs/2412.13435
Related Posts
AI chatbots vs. AI agents: Which AI tool fits your business needs?
AI tools are everywhere—but are you using the right one? […]
![]()
Create Proposals with AI. Win Faster and Bigger.
There’s nothing quite like the excitement of winning a Request […]
![]()
2024 Recap: AI Trends That Redefined What’s Possible
2024 is coming to an end, and this year has […]
![]()
Unwrapping Trends and Outcomes in Retail
With every holiday season, retailers face the most critical period […]
![]()
Tula Masterman
Principal Data Scientist with Applied AI Expertise
Subscribe
Sign up for emails on new digital articles and other news
Subject to Neudesic’s Privacy Policy, you agree to allow Neudesic to use your contact details to keep you informed about products, services, and offers. You can opt-out at any time.
Leave a Reply